| 网络虚拟化 |
|
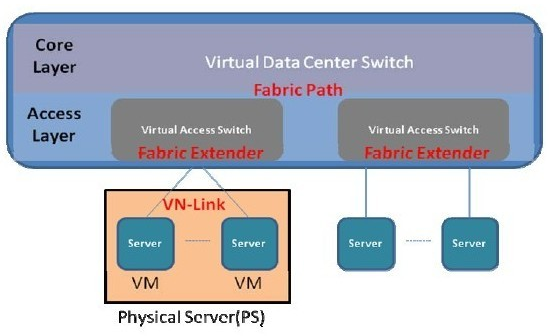
云计算就是计算虚拟化,而存储虚拟化已经在SAN上实现得很好了,那么为什么还要网络虚拟化呢,云计算多虚一时,所有的服务资源都成为了一个对外的虚拟资源,那么网络不管是从路径提供还是管理维护的角度来说,都得跟着把一些机框盒进行多虚一统一规划。而云计算一虚多的时候,物理服务器都变成了一些VM 网络多虚一技术 网络多虚一技术:最早的网络多虚一技术代表是交换机集群Cluster技术,多以盒式小交换机为主,较为古老,当前数据中心里面已经很少见了。而新的技术则主要分为两个方向,控制平面虚拟化与数据平面虚拟化。 控制平面虚拟化 顾名思义,控制平面虚拟化是将所有设备的控制平面合而为一,只有一个主体去处理整个虚拟交换机的协议处理,表项同步等工作。从结构上来说,控制平面虚拟化又可以分为纵向与横向虚拟化两种方向。 纵向虚拟化指不同层次设备之间通过虚拟化合多为一,代表技术就是Cisco的Fabric Extender,相当于将下游交换机设备作为上游设备的接口扩展而存在,虚拟化后的交换机控制平面和转发平面都在上游设备上,下游设备只有一些简单的同步处理特性,报文转发也都需要上送到上游设备进行。可以理解为集中式转发的虚拟交换机。 横向虚拟化多是将同一层次上的同类型交换机设备虚拟合一, Cisco的VSS/vPC和H3C的IRF都是比较成熟的技术代表,控制平面工作如纵向一般,都由一个主体去完成,但转发平面上所有的机框和盒子都可以对流量进行本地转发和处理,是典型分布式转发结构的虚拟交换机。Juniper的QFabric也属于此列,区别是单独弄了个Director盒子只作为控制平面存在,而所有的Node QFX3500交换机同样都有自己的转发平面可以处理报文进行本地转发。 控制平面虚拟化从一定意义上来说是真正的虚拟交换机,能够同时解决统一管理与接口扩展的需求。但是有一个很严重的问题制约了其技术的发展。在前面的云计算多虚一的时候也提到过,服务器多虚一技术目前无法做到所有资源的灵活虚拟调配,而只能基于主机级别,当多机运行时,协调者的角色(等同于框式交换机的主控板控制平面)对同一应用来说,只能主备,无法做到负载均衡。网络设备虚拟化也同样如此,以框式设备举例,不管以后能够支持多少台设备虚拟合一,只要不能解决上述问题,从控制平面处理整个虚拟交换机运行的物理控制节点主控板都只能有一块为主,其他都是备份角色(类似于服务器多虚一中的HA Cluster结构)。总而言之,虚拟交换机支持的物理节点规模永远会受限于此控制节点的处理能力。这也是Cisco在6500系列交换机的VSS技术在更新换代到Nexus7000后被砍掉,只基于链路聚合做了个vPC的主要原因。三层IP网络多路径已经有等价路由可以用了,二层Ethernet网络的多路径技术在TRILL/SPB实用之前只有一个链路聚合,所以只做个vPC就足矣了。另外从Cisco的FEX技术只应用于数据中心接入层的产品设计,也能看出其对这种控制平面虚拟化后带来的规模限制以及技术应用位置是非常清晰的。 数据平面虚拟化 前面说了控制平面虚拟化带来的规模限制问题,而且短时间内也没有办法解决,那么就想个法子躲过去。能不能只做数据平面的虚拟化呢,于是有了TRILL和SPB。关于两个协议的具体细节下文会进行展开,这里先简单说一下,他们都是用L2 ISIS作为控制协议在所有设备上进行拓扑路径计算,转发的时候会对原始报文进行外层封装,以不同的目的Tag在TRILL/SPB区域内部进行转发。对外界来说,可以认为TRILL/SPB区域网络就是一个大的虚拟交换机,Ethernet报文从入口进去后,完整的从出口吐出来,内部的转发过程对外是不可见且无意义的。 这种数据平面虚拟化多合一已经是广泛意义上的多虚一了,相信看了下文技术理解一节会对此种技术思路有更深入的了解。此方式在二层Ethernet转发时可以有效的扩展规模范围,作为网络节点的N虚一来说,控制平面虚拟化目前N还在个位到十位数上晃悠,数据平面虚拟化的N已经可以轻松达到百位的范畴。但其缺点也很明显,引入了控制协议报文处理,增加了网络的复杂度,同时由于转发时对数据报文多了外层头的封包解包动作,降低了Ethernet的转发效率。 从数据中心当前发展来看,规模扩充是首位的,带宽增长也是不可动摇的,因此在网络多虚一方面,控制平面多虚一的各种技术除非能够突破控制层多机协调工作的技术枷锁,否则只有在中小型数据中心里面刨食的份儿了,后期真正的大型云计算数据中心势必是属于TRILL/SPB此类数据平面多虚一技术的天地。当然Cisco的FEX这类定位于接入层以下的技术还是可以与部署在接入到核心层的TRILL/SPB相结合,拥有一定的生存空间。估计Cisco的云计算数据中心内部网络技术野望如下图所示:(Fabric Path是Cisco对其TRILL扩展后技术的最新称呼)
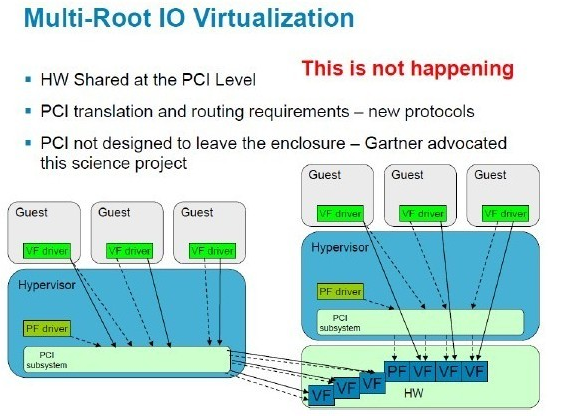
网络一虚多技术 网络一虚多,这个可是根源久远,从Ethernet的VLAN到IP的VPN都是大家耳熟能详的成熟技术,FC里面也有对应的VSAN技术。此类技术特点就是给转发报文里面多插入一个Tag,供不同设备统一进行识别,然后对报文进行分类转发。代表如只能手工配置的VLAN ID和可以自协商的MPLS Label。传统技术都是基于转发层面的,虽然在管理上也可以根据VPN进行区分,但是CPU/转发芯片/内存这些基础部件都是只能共享的。目前最新的一虚多技术就是Cisco在X86架构的Nexus7000上实现的VDC,和VM一样可以建立多个VDC并将物理资源独立分配,目前的实现是最多可建立4个VDC,其中还有一个是做管理的,推测有可能是通过前面讲到过的OS-Level虚拟化实现的。 从现有阶段来看,VDC应该是Cisco推出的一项实验性技术,因为目前看不到大规模应用的场景需求。首先转发层面的流量隔离(VLAN/VPN等)已经做得很好了,没有必要搞个VDC专门做业务隔离,况且从当前VDC的实现数量(4个)上也肯定不是打算向这个方向使劲。如果不搞隔离的话,一机多用也没有看出什么实用性,虚拟成多个数据中心核心设备后,一个物理节点故障导致多个逻辑节点歇菜,整体网络可靠性明显降低。另外服务器建VM是为了把物理服务器空余的计算能力都用上,而在云计算数据中心里面网络设备的接口数应该始终是供不应求的,哪里有多少富裕的还给你搞什么虚拟化呢。作者个人对类似VDC技术在云计算数据中心里面的发展前景是存疑的。 SR-IOV 对网络一虚多这里还有个东西要补充一下,就是服务器网卡的IO虚拟化技术。单根虚拟化SR-IOV是由PCI SIG Work Group提出的标准,Intel已经在多款网卡上提供了对此技术的支持,Cisco也推出了支持IO虚拟化的网卡硬件Palo。Palo网卡同时能够封装VN-Tag(VN的意思都是Virtual Network),用于支撑其FEX+VN-Link技术体系。现阶段Cisco还是以UCS系列刀片服务器集成网卡为主,后续计划向盒式服务器网卡推进,但估计会受到传统服务器和网卡厂商们的联手狙击。 SR-IOV就是要在物理网卡上建立多个虚拟IO通道,并使其能够直接一一对应到多个VM的虚拟网卡上,用以提高虚拟服务器的转发效率。具体说是对进入服务器的报文,通过网卡的硬件查表取代服务器中间Hypervisor层的VSwitch软件查表进行转发。另外SR-IOV物理网卡理论上加块转发芯片,应该可以支持VM本地交换(其实就是个小交换机啦),但个人目前还没有看到实际产品。SR(Single Root)里面的Root是指服务器中间的Hypervisor,单根就是说目前一块硬件网卡只能支持一个Hypervisor。有单根就有多根,多根指可以支持多个Hypervisor,但貌似目前单物理服务器里面跑多个Hypervisor还很遥远,所以多根IO虚拟化MR-IOV也是个未来未来时。摘录Cisco胶片对MR-IOV描述如下:(HW为Hardware,PF为Physical Function,VF为Virtual Functions)
SR-IOV只定义了物理网卡到VM之间的联系,而对外层网络设备来说,如果想识别具体的VM上面的虚拟网卡vNIC,则还要定义一个Tag在物理网卡到接入层交换机之间区分不同vNIC。此时物理网卡提供的就是一个通道作用,可以帮助交换机将虚拟网络接口延伸至服务器内部对应到每个vNIC。Cisco UCS服务器中的VIC(Virtual Interface Card)M81-KR网卡(Palo),就是通过封装VN-Tag使接入交换机(UCS6100)识别vNIC的对应虚拟网络接口。 网络虚拟化技术在下一个十年中必定会成为网络技术发展的重中之重,谁能占领制高点谁就能引领数据中心网络的前进。从现在能看到的技术信息分析,Cisco在下个十年中的地位仍然不可动摇。 |
- 1
- 2
- 3
- 4
- 5